TypeScriptでBase64を自作します。Denoの場合標準ライブラリにBase64が実装されていますので実際に利用する際はそちらを使ってください。
完成品
一応Denoパッケージとしても公開しています。
https://github.com/kota-yata/ky_base64
処理の流れ
エンコーダー
Base64エンコードの大まかな流れは、
- 文字列のバイナリーを6bitsで区切る
- 余ったビットは末尾に0を加えて6bitsにする
- 予め定められている変換表に対応する文字に変換する
- 文字数が4の整数倍に満たない場合は=で埋め合わせる
という、割と単純なアルゴリズムです。最も楽に書きたいのであればバイナリーを文字列として扱うのが良いでしょう(8bits⇨6bitsが非常に楽)。しかしそれはすでに非推奨になっている、Windowオブジェクトのbtoa()がやっていたことであり、2021年に許される書き方ではありません。なので今回はバイナリーをバイナリーとして扱って実装します。
デコーダー
デコーダーの処理の流れは
- 変換表に沿って文字を6bitsに変換する
- 6bitsから8bitsに区切り直す
- UTF-8デコードで文字列にする
こちらも同様にバイナリーはバイナリーとして扱います。
実装
エンコーダー
文字列をUTF-8コードに変換する
const encoder = new TextEncoder();
const uint8Array = encoder.encode(str); // strは入力の文字列
JavaScriptの内部エンコーディングはUTF-16なのでstr.charCodeAt(n)をするとUTF-16の値が返ってくるのですが、幸いTextEncoderを使えばUTF-8のストリームをTypedArray (Uint8Array)で受け取れます。これが無いとUTF-8エンコーダーを自作する必要があったので本当にありがたいです。
シフト演算で6bitsに切り分ける
Uint8Arrayからいきなり6bitsに分けることはできないので、各8bitsをシフト演算で切り分け、前の8bitsの後ろ部分と次の8bitsの前部分を足して6bitsの値を作ります。
const splitNum = (num: number, i: number) => {
let bitsToShift = 0;
const mod = i % 3;
if (mod === 0 || mod === 3) {
bitsToShift = 2;
} else if (mod === 1) {
bitsToShift = 4;
} else if (mod === 2) {
bitsToShift = 6;
}
const mainBits = (num >>> bitsToShift);
const extraBits = (num << (6 - bitsToShift)) % 64;
return { mainBits, extraBits };
};
splitNumはUTF-8のエンコード値とその値の配列内インデックスを渡されます。数値を区切る位置を決めるには前の数値の後ろ部分がどれだけ残ったかがわかる必要があります。純粋にやるならその値も引数として渡してしまうという手がありますが、実は8bitsから6bitsを切り分けていくと、区切る位置に周期が見られます。

上の画像のように、周期を3として2,4,6,2,4,6…と区切る位置が繰り返しになっている、つまりbitsToShiftに格納し、前部分は符号なし右シフト、後ろ部分は左シフトの後64(2の6乗)のmodをとって6bitsに収めます。
const convert8to6 = (uint8Array: Uint8Array) => {
let extra = 0;
const new6BitsArray: number[] = [];
for (let i = 0; i < uint8Array.length; i++) {
const num = uint8Array[i];
const splitted = splitNum(num, i);
const main = splitted.mainBits + extra;
new6BitsArray.push(main);
if (i % 3 === 2 || i === uint8Array.length - 1) {
new6BitsArray.push(splitted.extraBits);
extra = 0;
} else {
extra = splitted.extraBits;
}
}
return new6BitsArray;
};
上のコードにおいて、convert8to6の入力はUTF-8のエンコード結果です。その数値一つ一つをsplitNumに渡し、刻まれた前部分をextraに格納されている、前の数値の後ろ部分と加算します。splitNumが正しく動作すればその結果は必ず6bits(0~63)に収まるので、それをnew6BitsArrayに入れて返り値とします。上で述べたように区切る位置の周期は3で、6ビット目で区切るループの際はextraBitsも6bitsになります。そして配列の最後も0を詰めて6bitsにする決まりなので、extraBitsも結果に出力します。それ以外の場合はextraBitsを次の数値の前部分と足すためにextra変数に一時的に代入します。
最後のループの処理に0を詰める処理がない理由は、extraBitsはsplitNum関数ですでに左ビットシフトされており、その時点で余った部分に0が詰められているからです。
変換表を使って6bitsを文字列に変換する
Base64で使われる表は以下の通りです。(表書くのめんどいので画像です)
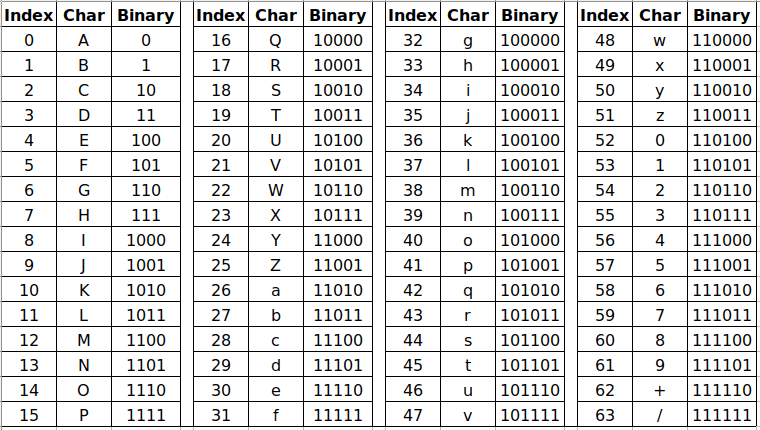
const base64Chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
const generateEncodeResult = (new6BitsArray: number[]): string => {
const mod4 = new6BitsArray.length % 4 === 0
? 0
: 4 - (new6BitsArray.length % 4);
let result = "";
new6BitsArray.map((bits: number) => {
result += base64Chars[bits];
});
result += "=".repeat(mod4);
return result;
};
変換表は文字列としてbase64Charsに格納し、6bitsの数値をインデックスに検索します。最後に4の整数倍に満たない分=を加え、エンコーダーの完成です。
デコーダー
変換表に沿って文字を6bitsに変換し、そのまま8bitsに区切り直す
文字から数値に変換する処理と8bitsに区切り直す処理を分けてしまうと2回走査する必要があるので、まとめて一度にやってしまいます。
const base64ToUint8Array = (base64Str: string): Uint8Array => {
const strArray = base64Str.replace(/=/g, "").split("");
const lengthAs8Bits = (strArray.length * 6 / 8);
const result = new Uint8Array(lengthAs8Bits);
let connection = 0;
let uintIterator = 0; // Because not every process in the loop below pushes to result array.
for (let i = 0; i < strArray.length; i++) {
const tableIndex = base64Chars.indexOf(strArray[i]);
const mod = i % 4;
if (mod === 0) {
connection = tableIndex << 2;
continue;
}
const bitsToShift = 6 - mod * 2;
connection += tableIndex >>> bitsToShift;
result[uintIterator] = connection;
uintIterator++;
const extra = tableIndex << (8 - bitsToShift);
connection = extra % 256;
}
return result;
};
Base64ToUint8ArrayはBase64のエンコード文字列を引数に取ります。後にUTF-8デコードでTextDecoderクラスを使うのですが、その引数はUint8Arrayなのでこの関数でも返り値となるresult変数はUint8Arrayです。
8bitsに区切り直す過程はエンコーダーの時と似た感じで、周期を4として区切る位置が決まります。connectionに何も入っていない、つまり数値を区切る必要はなく6bits全てconnectionに代入すれば良いので例外処理として先に済ませています。それ以外の場合は6 - mod * 2で区切る位置が判明します。気になる方は6bitsを続けて書いて8bitsで刻んでみると区切り位置がこの式と一致しているのがわかると思います。そしてconnectionに左シフトを済ませた後ろ部分を代入して次のループに移ります。
resultに値を入れる際にforループのイテレータではなくuintIteratorなる別のイテレータを使っているのは、先に述べたように
UTF-8デコードで文字列に戻す
const uint8Array = base64ToUint8Array(encodedStr);
const decoder = new TextDecoder();
const result = decoder.decode(uint8Array);
return result;
エンコード時と同様にJSのTextDecoderクラスにお世話になります。Uint8Arrayを引数に渡せばデコード結果の文字列が返され、これがBase64のデコード結果になります。
おわりに
やはりこういうバイナリーを扱う処理にTSは向いてないですね。


